Back in August, my colleague Sam published a blog post about how we use data-driven analytics to make important product decisions. These situations happen every day at Zocdoc — whether we’re A/B testing the success of a new user experience or evaluating the success of our new Zocdoc Video Service telehealth platform. We depend on accurate and up-to-date views into every dimension of the business.
It’s not enough just to have lots of trustworthy data, however. We also need a robust technical infrastructure to keep that data fresh and available. At Zocdoc, that’s the job of the Data Engineering team.
Data Engineers like myself have multiple responsibilities since we support multiple teams. On the business side, we maintain and manage access to a data warehouse — a database specially designed to let users aggregate large datasets in their queries. On the engineering side, we build and deploy data pipelines to regularly add new data to our data warehouse. Engineers and product stakeholders are our customers. Clean, reliable data is the product.
What’s In A Data Warehouse?
When Zocdoc moved to AWS in 2015, our lift-and-shift philosophy launched our technology into the stratosphere. Unfortunately, data analytics, far from the domain of product engineering, just wasn’t a priority. Analysts and product stakeholders had no choice but to query a de-identified, read-only copy of our production database, but those queries could be slow or resource intensive since that database isn’t optimized for analytics. This problem only grew; as the business scaled, so did the size of our data.
The solution was to move analytics data to the cloud too. Since 2017, we’ve relied on Amazon’s Redshift product — a cloud-hosted data warehouse — to meet our needs. I’m happy to report that the choice paid off. Thanks to Redshift’s native integration with tools like Databricks, Amazon S3, and JetBrains Datagrip, we steadily migrated our analytics data to the cloud and supported it with a robust ETL infrastructure using AWS. Today, our analysts can answer complex business questions without having to start from scratch.
Suffering From Success
Migrating to a data warehouse brought Zocdoc’s analytics capabilities into the modern age. But as the business scaled, the needs of Zocdoc’s data ecosystem in 2020 outpaced the requirements from 2017. With an influx of terabytes of data, and dozens of new data-savvy Zocdoc’rs querying it, we needed to resize our warehouse four times from June 2017 to March 2019 — quadrupling our costs.
It became increasingly clear that the data engineering team’s bottlenecks lay with our configuration of Redshift itself, especially around its ability to scale within our budget. Unfortunately, Redshift’s pricing model wasn’t flexible in the way we needed. The only way to store more data was to purchase additional compute nodes, even if we didn’t actually need the extra compute power.
In addition, there were some pain points that were unable to be solved by Redshift’s features. For example, character-varying text columns had a big impact on query performance. There was also no support for a “staging” warehouse we could incorporate into our continuous integration process — we had to maintain a separate cluster and ensure parity on our own.
But the biggest obstacle was Redshift’s concurrency limits. Amazon’s guidelines recommend a maximum of fifteen concurrent users, and all queries have to compete against each other on a single cluster. Between the volume of automated and human users, the business’s querying needs just weren’t met with our current infrastructure, and our users felt the pain.
Upgrade Or Replace?
By January 2020, these issues had become too glaring to ignore. The team was too bogged down by CI problems and concurrency issues to work on the data itself, and our internal users were suffering from slow queries. We were faced with two options: exceed our budget to scale up Redshift and leave our systems intact, or explore other technologies that might have the desired features. Amazon offers a lot, but the time had come to research what else was out there.
Most technical folks are aware of Snowflake, the data warehouse technology company, thanks in part to its September IPO. But Snowflake had already been a hot topic in the data engineering industry for years. Why? When we started to approach this problem in January, their product had a key competitive advantage: Snowflake’s architecture lets its users scale up data storage and compute resources independently from each other, and at will. That means a temporary spike in usage doesn’t force us to provision more expensive nodes or experience service degradation.
Another nifty feature Snowflake offers is the ability to “clone” a database on demand. Since Snowflake tracks data modifications as a chain of changes, users can branch a database to create an identical one. In particular, we wanted to use clones during continuous integration to test changes to our schemas or transformations before rolling them out to production.
But again, we asked ourselves: could we get by sticking with Redshift? In December 2019, Amazon released a new type of node — the basic unit of storage and compute in a Redshift cluster. RA3 nodes differed from DC2 nodes (what we used) by providing the same advantage Snowflake offered: separated usage of storage and compute resources and a pay-what-you-used pricing model. Additionally, Amazon promised that our data warehouse could be upgraded to the new node type with only a few hours of interruption.
The Proof Of Concept
It was a difficult choice, but Snowflake as advertised had too many attractive features to pass up. Although Amazon’s RA3 might have reduced our performance issues just fine, it had only been out for a couple of months at that point. The team didn’t feel comfortable migrating to such a new and unproven technology, even if it did come from Amazon.
Thankfully, since the executive team felt the pain of slow analytics too, investing in Snowflake wasn’t a hard sell. Snowflake’s sales representatives were happy to provision a staging version of Snowflake so we could explore a proof-of-concept before we committed. With those hurdles out of the way, the plan could move forward.
Our main goal was to leave as much of our system in place as we could. There were just too many dependencies with too many stakeholders (many non-technical) relying on them. If a key dashboard became unavailable or pipeline caused data delays, the business could suffer. If we had chosen to redeploy Redshift with RA3 nodes, “lifting and shifting” might have been an option with only a few hours of downtime. But with Snowflake, that wasn’t a risk we could afford to take.
Thankfully, having a “sandbox” Snowflake account was the perfect opportunity to move fast without breaking things. There were three components to our plan:
- Recreate representative tables and views in Snowflake
- Double-write data to both Snowflake and Redshift by deploying identical pipeline stacks
- Ensure parity and functionality of our dependencies by deploying identical transformation stacks and dashboards
With help from Snowflake’s technical support (shout out to Frank Pacione) and comprehensive documentation, our experiment was pronounced a success in May of 2020. We liked the console interface, but most importantly, query performance met our goals. Zocdoc had become Snowflake’s newest customer.
The Migration
Although our proof of concept paved a clear road ahead in terms of technical work items, deploying real data to production systems brought a new set of challenges- and opportunities. Unlike the sandbox Snowflake account, accessible only by data engineers, the production data warehouse needed to be available to all internal Zocdoc users. Since the real-life data we were migrating includes sensitive datasets restricted to subsets of authorized users, we had the obligation — and creative freedom — to build an airtight, yet elegant approach to user management.
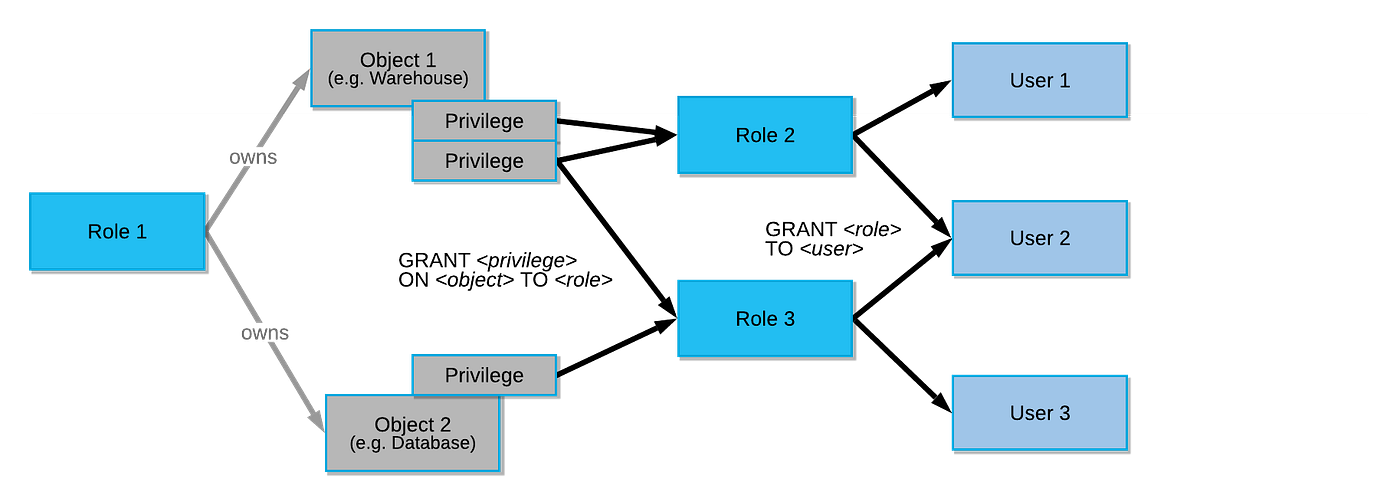
To accomplish this, we made use of another useful feature: role-based access to data. Redshift organizes access by user groups, but they tend to be opaque and can overlap as team responsibilities shift. Snowflake’s roles, on the other hand, are arranged in a hierarchy from org-wide to team-level to user-level. Team roles can be modified to match the organization of the business; users, in turn, can be assigned (or revoked) to multiple roles. We’re now able to manage data access more unambiguously and precisely.
Another improvement over the proof-of-concept migration was to automate certain steps. While developing the sandbox, we manually wrote and executed all the SQL statements for all of our tables, views, schemas, etc. Now, our learnings enabled us to script all of that out. Automation also saved us time later in the process, as we backfilled and QA’ed historical data. We couldn’t script everything, though. Since Snowflake’s syntax differs slightly from Redshift’s syntax, much of our ETL and transformation code needed to be adjusted by hand. One upside: we found opportunities to refactor the new code to be clearer and more performant.
Snowflake At Zocdoc: A Work In Progress
At the time of writing, the migration is still under way and time will tell if Zocdoc reaps all the benefits we are anticipating. But Snowflake has already delivered tremendous value.
When the COVID-19 pandemic first hit the U.S. in March 2020, Zocdoc rushed to launch its Zocdoc Video Service to help patients schedule telemedicine appointments as an alternative to in-person encounters. The datasets powering this product — necessary to assess its viability and value — were implemented in Snowflake thanks to its security advantages over Redshift. We delivered production-ready dashboards quickly, empowering the business to make Video Visits a success.
Progress is steady, but not without its challenges. Ironically, although most of the planning was spent on the technical implementation, the biggest hurdle right now is rolling out to our user base. Change management for new tools is never easy; especially not one as crucial to data users as a warehouse technology. As users adjust to new workflows and familiarize themselves with a different console, it’s up to the data engineering team to streamline that transition by providing technical support and user guides. It’s also our job to keep an eye out for opportunities to improve our infrastructure whenever reasonable. Migrations should be simple, but they shouldn’t force us to preserve old workarounds.
Successful migrations might not be as exciting as product rollouts, but without them, we’d be stuck with legacy systems powering our apps. This is a big step towards the future of data analytics at Zocdoc, and I’m excited to be a part of it.
About the Author
Gil Walzer is an engineer on the Zocdoc Data team. Before that, he developed backend tech on the Core Services team.
Zocdoc is hiring! Visit our Careers page for open positions!